
Teknoloji Haberleri

ChatGPT’ye Meydan Okuyan Llama 3: Meta’nın Yeni Hamlesi
Son yıllarda yapay zeka (AI) alanında büyük ilerlemeler kaydedildi. Meta şimdi de bu alanda adını duyurmak için Llama 3 adında...
Devamı...
Netflix Suç Belgeselinde Yapay Zeka Kullanmış Olabilir
Abone sayısı bakımından dünyanın en büyük dijital yayın platformlarından biri olan Netflix'in gerçek suç belgeselinde yapay zeka tarafından oluşturulan görüntü...
Devamı...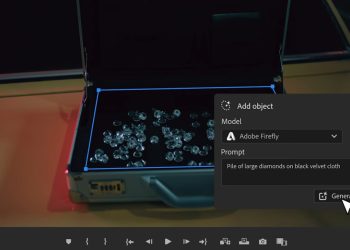
Adobe Premiere Pro’ya Yeni Yapay Zeka Özellikleri Getiriyor
Adobe, geçen yıl SenseiAI'ı temel alan yeni üretken yapay zeka modeli Adobe Firefly'ı piyasaya sürdü. Şimdi de bu yapay zeka...
Devamı...
xAI’ın Grok’u Görüntü İşleme Özelliği Kazanıyor
Elon Musk'ın kurduğu OpenAI rakibi xAI, Grok'un görüntü işleme özelliğini içeren ilk versiyonu tanıttı. Grok-1.5V, şirketin sadece metni değil aynı...
Devamı...
Windows 11’de Başlat Menüsüne Reklam Ekleniyor
Microsoft, Windows 11'de Başlat menüsüne reklam yerleştirmeyi amaçlıyor. Bu amaç doğrultusunda ise Microsoft Store'da bulunabilecek uygulamaları öne çıkarmak için menünün...
Devamı...
Apple, AI Modelini Eğitmek İçin Shutterstock ile Anlaştı
Apple, yapay zeka modellerini eğitmek için stok fotoğraf sağlayıcısı olan Shutterstock ile büyük bir anlaşmanın altına imza attı. Reuters tarafından...
Devamı...
Yapay Zeka ile Video Oluşturan Google Vids Duyuruldu
Belgeler, slaytlar, elektronik tablolar ve benzerlerinin gerek iş gerek eğitim hayatının artık olmazsa olmazlarından biri olduğu söylenebilir. Google, kullanıcılara bu...
Devamı...
Neuralink’in Çip Taktığı Hasta, Hayvan Deneyleri Hakkında Konuştu
Geçirdiği bir dalış kazasından dolayı 8 yıldır felçli olan 29 yaşındaki Noland Arbaugh, geçen günlerde Elon Musk'ın Neuralink beyin çipinin...
Devamı...
Meta’nın AI Görüntüleri İçin Yeni Politika İzliyor
Meta, yapay zeka modelleri tarafından oluşturulan görüntülerin bir AI aracı tarafından oluşturulduğunu net bir şekilde ortaya koymak adına önceden de...
Devamı...
YouTube, OpenAI’ı Kural İhlali Dolayısıyla Uyardı
İnternet kullanıcılarının çalışmalarını kullanarak eğitilen yapay zeka modelleri yeni bir şey değil. The New York Times ve Getty Images gibi...
Devamı...




Technotoday© 2009 Etna Yayıncılık - Technotoday.com.tr üzerine yayınlanan tüm içerikler kaynak belirtilmeden kullanılamaz.
